
Converting documents to Markdown and JSON at scale
A modern approach for AI/LLM practitioners


Every AI practitioner has encountered this situation: You possess thousands of documents in various formats—PDFs, Word files, Excel sheets, and web pages—that must be converted into a uniform format for your LLM training or AI pipeline.
Whether you’re training models, building AI applications, or creating knowledge bases, formatting your documents correctly is crucial yet often overlooked. This becomes particularly critical when processing large-scale documents for LLM and AI pipelines.
In this article, I will review the standard challenges, propose some solutions, and present my new micro-SaaS: Monkt (a tool for transforming documents and URLs into structured formats, like JSON or Markdown)
The document processing challenge
ML practitioners usually encounter three challenges when preparing documents for AI systems: format consistency, structural preservation, and scalability.
A research paper in PDF format, a technical specification in Word, and a sheet in Excel all contain valuable information, but converting them while maintaining their semantic structure requires careful handling.
Traditional methods often involve combining multiple Python libraries:
# Common approach using multiple libraries
from pdf2text import convert_pdf
from docx import Document
from bs4 import BeautifulSoup
import pandas as pd
def convert_document(file_path):
if file_path.endswith('.pdf'):
return convert_pdf(file_path)
elif file_path.endswith('.docx'):
doc = Document(file_path)
return '\n'.join([p.text for p in doc.paragraphs])
# Add more formats...This approach becomes unwieldy when managing multiple formats and scaling to thousands of documents.
It also frequently fails to maintain critical structural elements such as tables, headers, and image contexts.
Open source tools and their limitations
Next, we come to open-source tools like Microsoft’s MarkItDown, which provide solid foundations for document conversion.
While these tools offer great processing capabilities, they present specific implementation challenges.
from markitdown import MarkItDown
from openai import OpenAI
client = OpenAI()
md = MarkItDown(llm_client=client, llm_model="gpt-4o")
result = md.convert("example.pdf")This implementation, though working fine in general, comes with several technical constraints:
Server infrastructure configuration required for production deployment;
Output is limited to markdown format without JSON transformation capabilities;
Additional engineering needed for concurrent processing (implementing ThreadPoolExecutor, asyncio);
Lack of built-in schema validation for structured data extraction.
These implementation requirements show fundamental challenges in scaling document processing pipelines.
Cloud solutions for document processing
After years of building AI applications, I solved the same document processing challenges repeatedly. Each project required converting various document formats while preserving their structure, handling batch processing, and generating consistent outputs for AI pipelines.
Rather than continuing to build custom solutions for each project, I turned my document processing workflow into a micro-SaaS solution called Monkt.
The core idea was simple: create a reliable, scalable system that could handle document conversion and structure preservation without requiring a complex infrastructure setup.
I focused on three key capabilities essential in my work: automated format handling, consistent structure preservation, and flexible output formats through JSON schemas.
The result is a cloud-based solution that other AI practitioners can easily integrate into their workflows through API calls or a web interface (Python client soon).
You can find a screenshot of the dashboard below:

Below is a schema that briefly explains the flow with Monkt:

The schema illustrates the document processing pipeline. Input documents (PowerPoint, Word, Excel, PDF, CSV, Web pages, images) undergo initial processing to generate a standardized Markdown (MD) file.
This intermediate format enables two distinct processing paths: predefined prompts for generating structured Markdown and JSON outputs or JSON schema validation for generating schema-compliant data structures.

A key advantage of this architecture is the caching layer. Once a document is processed, subsequent retrievals are significantly faster since the system serves the cached version rather than processing the document again. This means teams accessing the same documents repeatedly benefit from near-instant delivery times, making it appropriate for collaborative environments and high-traffic scenarios.
The ability to consistently convert and structure documents at scale creates opportunities, from preparing training data to building a knowledge base.
In the next section, I will examine some common scenarios where document processing is essential.
Applications in AI development
AI development has many different directions nowadays. Each of them has unique recipes that can make the work process smoother.
Let’s start with the training flow.
1. Training data preparation
When preparing training data for LLMs, consistency is key.
Consider this approach for processing research papers:
def prepare_training_data(documents):
processed_data = []
for doc in documents:
# Convert to markdown while preserving structure
content = process_document(doc)
# Extract and structure key components
structured_content = {
'title': extract_title(content),
'abstract': extract_abstract(content),
'sections': parse_sections(content),
'references': extract_references(content)
}
processed_data.append(structured_content)
return processed_dataModern document processing solutions transform this preparation phase into a more manageable task.
Rather than building custom extractors for each document type, teams can use standardized pipelines that maintain consistency across diverse sources.
Such a systematic approach ensures that whether you’re working with academic papers, technical documentation, invoices, or research reports, the essential structural elements and relationships are preserved — a crucial factor for developing effective language models.
2. Knowledge base construction
Building AI-powered knowledge bases requires maintaining relationships between documents while making content searchable:
def build_knowledge_base(documents):
kb = {}
for doc in documents:
# Convert to markdown or JSON
processed = convert_to_structured_format(doc)
# Extract metadata and relationships
metadata = extract_metadata(processed)
relationships = identify_relationships(processed)
# Store with proper indexing
kb[doc.id] = {
'content': processed,
'metadata': metadata,
'relationships': relationships
}
return kbAdvanced document processing enhances knowledge base construction beyond simple text extraction.
When documents undergo processing through structured pipelines, their metadata, and internal relationships become programmatically discoverable.
This allows for automatically identifying themes, cross-references, and hierarchical relationships, resulting in interconnected knowledge graphs rather than isolated document repositories.
The resulting structure facilitates AI applications, ranging from enhanced search capabilities to reasoning tasks.
3. Web scraping to structured data
Converting web content into structured data for AI processing requires maintaining semantic meaning:
def scrape_and_structure(urls):
structured_data = []
for url in urls:
# Fetch and convert to markdown
content = fetch_and_convert(url)
# Extract structured data
article = {
'title': extract_title(content),
'author': extract_author(content),
'date': extract_date(content),
'content': segment_content(content),
'tags': extract_tags(content)
}
structured_data.append(article)
return structured_dataCloud-based document processing addresses many traditional web scraping challenges. Converting web content to intermediate formats like Markdown before applying structure helps normalize various website formats. Caching mechanisms prevent unnecessary re-processing of unchanged content, reducing both computational overhead and load on source websites.
Having covered the technical implementation details and architectural considerations, let’s examine proven approaches for robust document processing pipelines. These practices emerge from real-world implementations and address common challenges in maintaining document structure, handling diverse formats, and ensuring processing reliability at scale.
Best practices for document processing
Semantic structure preservation
During conversion, keep the document hierarchy intact. Headers, sections, and lists must maintain relationships to ensure proper content understanding. This means preserving the structure of headings, code blocks, and references in their correct order and nesting level for technical documents.
Mixed content handling
Process text and non-text elements consistently. Extract text descriptions from images, maintain table structures, and preserve formatting indicators. Create standardized metadata for non-text content to ensure it remains meaningful after conversion.
Quality validation
Run automated checks against defined schemas. Test for mistakes like malformed headers, broken lists, or corrupted tables. Implement validation rules that catch structural errors and format inconsistencies before they affect downstream applications.
Scalable processing
Design pipelines for high-volume document processing. Use batch operations to handle multiple files efficiently.
Implement parallel processing where possible and optimize resource usage during conversion tasks.
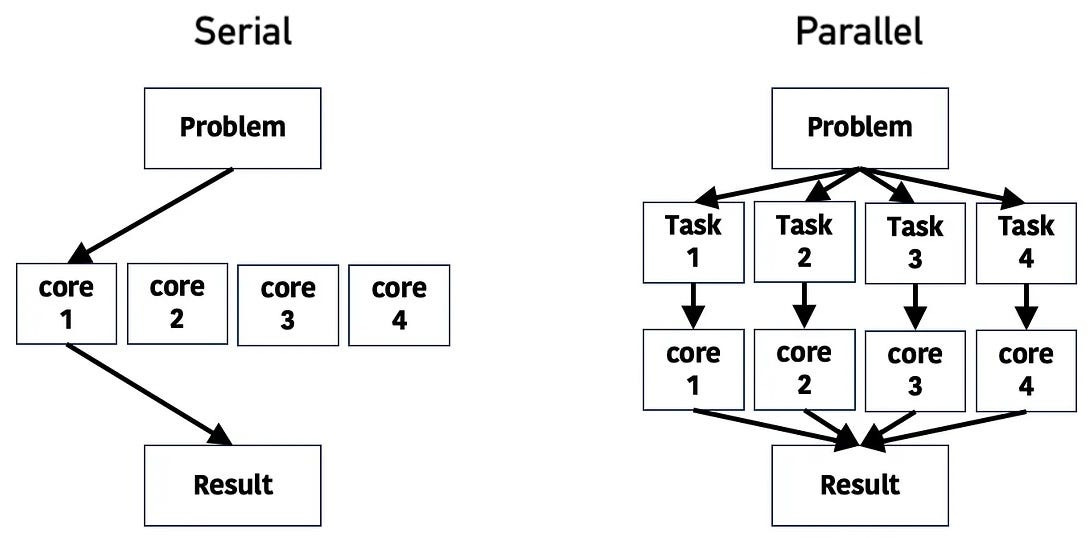
Add caching mechanisms to prevent redundant processing of unchanged documents.
This approach balances essential technical requirements with practical implementation needs. Each practice directly addresses common challenges in document processing while maintaining system reliability at scale.
Looking forward
Looking ahead, document processing infrastructure is evolving in lockstep with advances in AI systems. As language models grow, they demand increasingly structured and consistent input data.
For AI practitioners building document-intensive applications, the quality of document conversion and structuring directly impacts both model training efficiency and inference accuracy.
As we look to the future, the capability to manage more complex document types, enhance processing efficiency, and accommodate new AI model architectures will become increasingly important. Teams developing AI systems must thoroughly assess their document processing needs and implement solutions that scale with their expanding requirements.
Investing in robust document processing infrastructure today will shape the success of AI applications tomorrow.
This technological evolution offers both challenges and opportunities. By concentrating on scalable architectures, standardized outputs, and efficient processing pipelines, teams can develop document processing systems that address current needs and adapt to future advancements in AI tech.
Thanks for reading; if you liked my content and want to support me, the best way is to —
Connect with me on LinkedIn and GitHub, where I keep sharing such free content to become more productive at building ML systems.
Follow me on X (Twitter) and Medium to get instant notifications for everything new.
Join my YouTube channel for upcoming insightful content.
Check my special content on my website.