
Direct Preference Optimization (DPO) in Language Model Alignment
Implementations by OpenAI, Unsloth, and Hugging Face


Language models have transformed how we interact with the world around us. They can now write coherently, translate between languages, and engage in meaningful dialogue with impressive quality. In this context, researchers introduced an innovative approach called Direct Preference Optimization (DPO) in their paper “Your Language Model is Secretly a Reward Model“ which fundamentally changed how we consider aligning AI systems with human intent.
As these models integrate into various areas, from customer support to creative writing, it has become essential to ensure they behave in ways that meet human expectations. DPO plays a role in providing a cleaner and more efficient solution to the alignment challenge.
Traditional approaches to aligning language models generally fall into two categories: those based on reinforcement learning and those investigating alternative methods. DPO fits into the second category but with a unique twist. Instead of depending on complex reward modeling, it adopts a more straightforward approach-directly incorporating human feedback into the model’s learning process. This elegant method simplifies what has traditionally been a complicated alignment process.
This article will explore how DPO operates behind the scenes, examine its strengths and limitations, and consider where it can be most effectively applied. We will mention practical implementations by OpenAI and Unsloth, analyze performance comparisons with RLHF, and provide developers with essential tools and resources for integrating DPO into their projects.

Understanding DPO’s mechanics
DPO introduces a new method for training language models by simplifying what has typically been a complicated process. Unlike traditional approaches that depend on separate reward models and complicated reinforcement learning algorithms, DPO uses human feedback to directly refine the model’s behavior.
The process is straightforward: DPO learns from a dataset of human preferences. Each entry in this dataset contains a prompt and two possible responses — one that humans preferred and one that they didn’t. The system then learns to generate responses that align with these human preferences. This is notably different from traditional methods like RLHF (Reinforcement Learning from Human Feedback), which require a separate model to evaluate and guide the learning process.
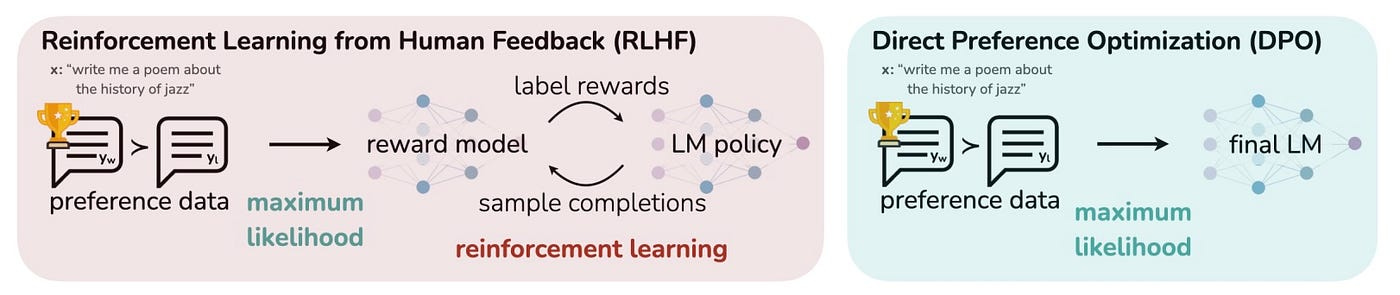
DPO stands out for its elegant approach to evaluating responses. Instead of relying on a separate component to assess output quality, DPO integrates this capability directly into the model. It’s like teaching the model not only how to generate responses but also how to evaluate those responses based on human preferences.
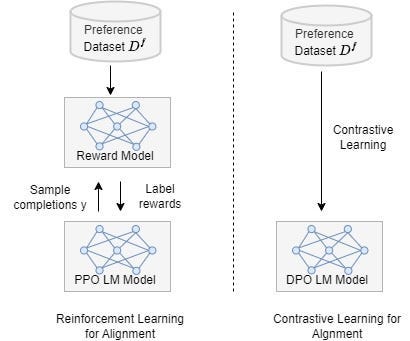
The core technical innovation of DPO is its mathematical foundation, which is the model’s behavior and human preferences. This approach eliminates the need for intermediate steps. The model learns using a specialized function that compares the likelihood of generating preferred responses against those less preferred. This direct method allows the model to align more naturally with human preferences.
DPO vs. Traditional optimization methods
Traditional methods, like RLHF, use a separate reward model to evaluate and guide the training process. In contrast, DPO takes a different approach. It directly integrates human feedback into the model’s training, streamlining the process and reducing the potential biases that may arise from using an intermediate reward model.
Another significant difference is in the training process itself. RLHF involves repeatedly sampling from the language model during training, which makes the tuning process computationally intensive and complex. On the other hand, DPO simplifies this by directly optimizing the model based on human preference data, requiring less fine-tuning and technical overhead.
Let’s break down the key differences between DPO and RLHF:

Experimental validation and performance analysis
The empirical effectiveness of DPO is especially evident in two key experimental scenarios, as shown in the figure below. These results highlight both DPO’s theoretical advantages and its practical superiority over existing methods.
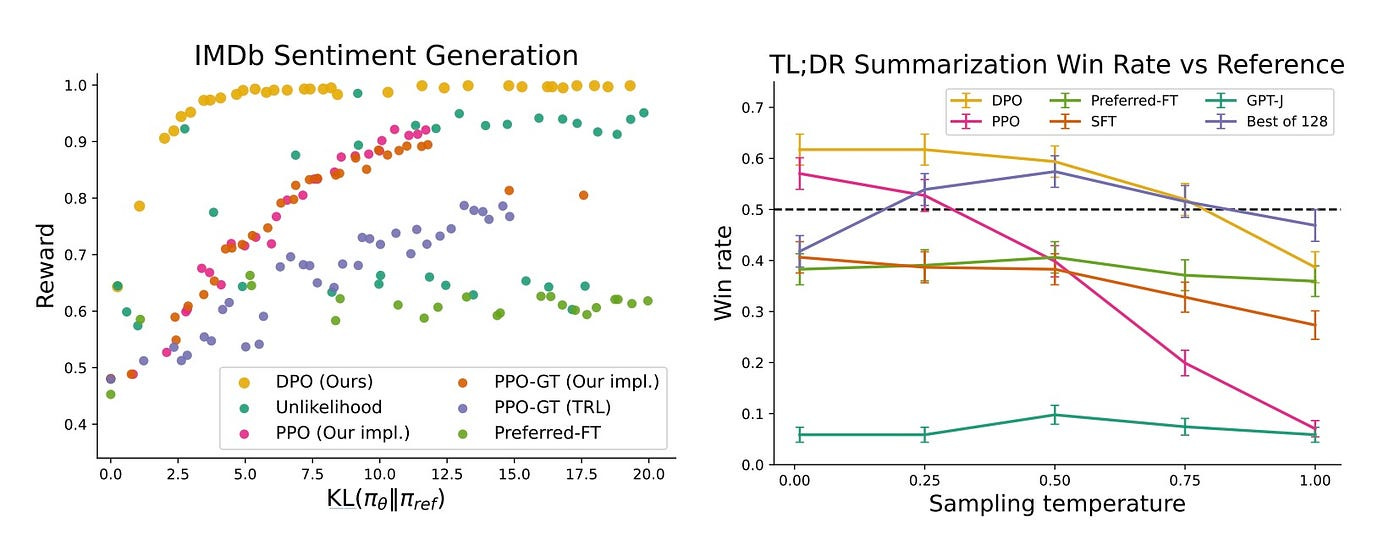
Understanding the results
The left panel shows performance on IMDb sentiment generation ( siebert/sentiment-roberta-large-english as a ground-truth reward model and gpt2-large as a base model), plotting reward versus KL-divergence (a measure of how much the model’s behavior deviates from its initial training). KL-divergence, in simple terms, quantifies the “distance” between two probability distributions — here, between the optimized model and its reference version. A lower KL divergence indicates the model maintains more of its original behavior while learning new preferences.
DPO (shown in yellow) consistently achieves higher rewards across all KL-divergence values, indicating it learns desired behaviors more efficiently than alternative approaches. Notably, it outperforms both standard PPO (Proximal Policy Optimization) implementations and even PPO with ground-truth rewards (PPO-GT).
The right panel demonstrates real-world application through TL;DR summarization tasks, measuring win rates against reference summaries across different sampling temperatures. DPO maintains superior performance even as sampling temperature increases, showing remarkable robustness compared to PPO’s dramatic performance degradation at higher temperatures.
Key insights
DPO achieves better preference alignment while maintaining closer proximity to the reference model;
The method demonstrates greater stability across different sampling temperatures;
Performance benefits persist even in practical summarization tasks.
The pros and cons of DPO
Key benefits
DPO’s strength lies in its direct approach to aligning language models with human preferences. At its core, DPO cuts through the complexity of traditional methods, offering several distinct advantages.
First and foremost, DPO’s direct optimization approach leads to faster and more effective alignment with human preferences. By bypassing intermediate steps, the training process becomes more streamlined and efficient. This directness also helps reduce potential biases that might creep in through intermediate reward models.
From a practical standpoint, DPO is notably efficient in terms of both computational resources and data usage. This efficiency doesn’t come at the cost of performance — in fact, DPO often matches or exceeds traditional methods in achieving alignment with human preferences. The training process also tends to be more stable, with fewer common issues like overfitting that plague other methods.
Limitations
However, DPO isn’t without its challenges. Understanding these limitations is essential for deciding whether it’s the right choice for a specific project.
The most significant drawback is DPO’s tendency to overfit its training data. While techniques like Identity Preference Optimization (IPO) have been developed to address this, it remains a concern that requires careful monitoring. The model also shows particular sensitivity to the quality of its initial training, especially during the Supervised Fine-Tuning (SFT) phase.
DPO’s reliance on binary preferences (essentially “this or that” choices) can be limiting when dealing with scenarios that require more nuanced feedback. This binary nature might not capture the full complexity of human preferences in certain situations. Additionally, the model sometimes struggles when comparing similar responses, potentially limiting its ability to make fine distinctions in preference learning.
Another practical challenge is data requirements. DPO needs a substantial amount of high-quality preference data to operate effectively. This can pose a significant hurdle for projects with limited data resources or for those working in specialized domains where such data is difficult to obtain.
These strengths and limitations suggest that while DPO is a powerful tool, its implementation should be carefully considered based on specific project needs, available resources, and the complexity of the task.
Real-world applications of DPO
DPO’s practical applications span various language model tasks, from everyday chatbots to complex AI agent systems.
It can be a part of any LLM section from the diagram below:
But that’s not all; here are some other actual use cases:
Customer service and conversation
The most visible impact of DPO is in conversational AI. Customer service chatbots trained with DPO show marked improvements in their ability to engage naturally with users. Take a typical customer support scenario: DPO-enhanced chatbots provide accurate information and do so with appropriate empathy and tone, leading to more satisfying customer interactions.
Content generation and management
DPO has proven valuable in refining how language models handle various content tasks:
Text summarization becomes more focused and relevant, with summaries that better match human preferences for clarity and conciseness;
Sentiment and tone control becomes more precise, allowing for better alignment with brand voice or specific communication needs;
Question-answering systems show improved accuracy and relevance in their responses.
Advanced applications
Beyond these common uses, DPO is finding its way into more specialized applications.
Research teams use DPO to evaluate and improve few-shot learning strategies, helping models adapt to new tasks with minimal training. The technology also serves as a benchmark for assessing embedding model quality, assisting researchers to understand how well their models capture and represent information.
One auspicious development is Step-DPO, a variant designed to enhance models’ reasoning capabilities. This adaptation has shown significant potential in improving models' handling of complex, multi-step problems, especially in mathematical reasoning.
Emerging use cases
The range of DPO applications continues to grow. Teams are exploring its use in:
Code generation and review systems;
Educational tools that adapt to student learning preferences;
Content moderation systems that better align with human judgment;
Document analysis tools that can better prioritize relevant information.
This versatility demonstrates DPO’s potential as a key tool in developing more capable and user-aligned AI systems.
Resources and tools
Several tools and resources are available for developers and researchers interested in implementing DPO. Here’s a practical list of some of them.
Essential development tools
Hugging Face TRL library
The Transformers Reinforcement Learning (TRL) library from Hugging Face stands out as the go-to resource for DPO implementation. It provides a comprehensive toolkit for fine-tuning language models, with well-documented examples and ready-to-use implementations.
Unsloth framework
Unsloth offers an innovative approach by combining DPO with QLoRA and LoRA techniques. This integration significantly speeds up the fine-tuning process, making it particularly valuable for teams with limited computational resources.
What makes Unsloth particularly innovative is its novel approach to memory management and computation. By combining QLoRA’s quantization benefits with LoRA’s parameter-efficient training, and then optimizing these specifically for DPO workflows, Unsloth achieves remarkable performance gains. The framework can reduce VRAM usage by up to 30% while enabling batch sizes twice as large as traditional implementations.
The framework recently expanded its capabilities to include ORPO (Odds Ratio Preference Optimization), which streamlines the training process even further by merging supervised fine-tuning and preference learning into a single step. This advancement is particularly valuable for teams working on alignment tasks with limited computational resources.
Here’s a practical example of how Unsloth accelerates DPO training. Consider fine-tuning a Zephyr model on preference data. Traditional approaches might require separate stages for supervised learning and preference optimization. With Unsloth, you can implement this efficiently using their optimized DPOTrainer:
from unsloth import FastLanguageModel, PatchDPOTrainer, PatchDPOTrainer() # Essential step for optimization
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/zephyr-sft-bnb-4bit",
max_seq_length = 4096,
load_in_4bit = True # Enables efficient quantization
)
# Add optimized LoRA weights with Unsloth's special configurations
model = FastLanguageModel.get_peft_model(
model,
r = 64, # LoRA rank for parameter efficiency
target_modules = ["q_proj", "k_proj", "v_proj", "o_proc"],
use_gradient_checkpointing = "unsloth" # Enables 30% VRAM savings
)The framework provides documentation and practical examples through Google Colab notebooks, demonstrating implementations for both DPO and ORPO approaches. For hands-on experimentation, developers can access these through the DPO Zephyr notebook or the ORPO notebook.
These optimizations make Unsloth particularly valuable for research teams and smaller organizations that need to perform model alignment but don’t have access to extensive computational resources. The framework’s efficiency gains often mean the difference between requiring expensive GPU clusters and being able to run meaningful experiments on more modest hardware.
Learning resources
PyTorch implementation guide
For those who prefer hands-on learning, there’s a detailed Jupyter Notebook available on GitHub that walks through DPO implementation using PyTorch and the Hugging Face ecosystem. This resource is especially valuable for understanding the practical aspects of implementation.
Hugging Face workshop materials
Hugging Face’s workshop on DPO provides a thorough introduction to both theory and practice. It covers:
Core concepts and implementation details;
Practical examples and use cases;
Performance evaluation methods;
Common pitfalls and how to avoid them.
These resources provide a solid foundation for anyone looking to integrate DPO into their language model projects, whether for research or practical applications.
OpenAI and DPO
OpenAI recently brought DPO to their platform, making it available alongside their new vision fine-tuning features.
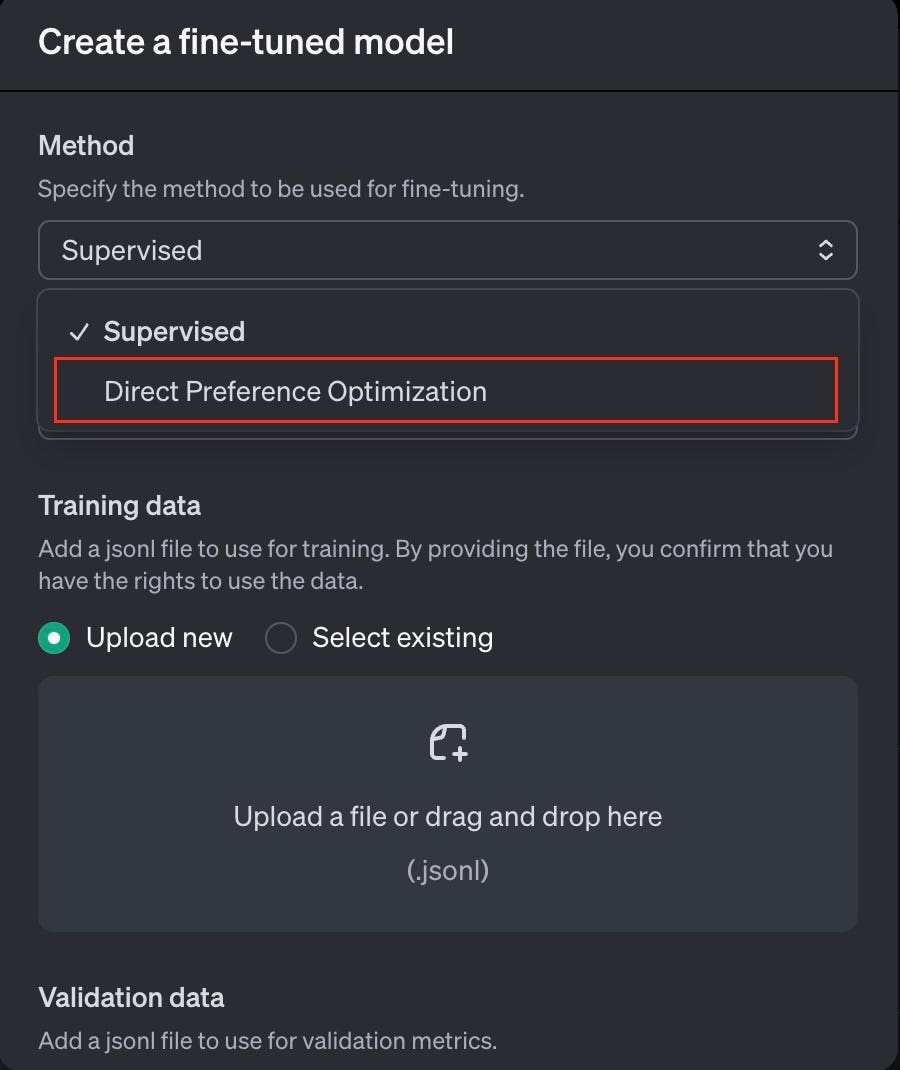
Their take on DPO is straightforward but powerful — developers can feed the system pairs of responses (one preferred, one not) along with the original prompts, all packaged in a JSONL format.
{
"input": {
"messages": [
{
"role": "user",
"content": "Hello, can you tell me how cold San Francisco is today?"
}
],
"tools": [],
"parallel_tool_calls": true
},
"preferred_output": [
{
"role": "assistant",
"content": "Today in San Francisco, it is not quite cold as expected. Morning clouds will give away to sunshine, with a high near 68°F (20°C) and a low around 57°F (14°C)."
}
],
"non_preferred_output": [
{
"role": "assistant",
"content": "It is not particularly cold in San Francisco today."
}
]
}Instead of jumping straight into DPO, OpenAI suggests starting with regular supervised fine-tuning to teach the model the basics, then using DPO to refine its behavior. Think of it like teaching someone to cook — first they learn the fundamentals, then they develop their own style. To give developers precise control, OpenAI included a “beta” setting that determines how much the model sticks to its old ways versus adopting new preferences. Set it low, and the model eagerly embraces the new preferences; set it high, and it stays more conservative.
from openai import OpenAI
client = OpenAI()
job = client.fine_tuning.jobs.create(
training_file="file-all-about-the-weather",
model="gpt-4o-2024-08-06",
method={
"type": "dpo",
"dpo": {
"hyperparameters": {"beta": 0.2},
},
},
)Currently, you can only train on one-turn conversations for each example, where the preferred and non-preferred messages need to be the last assistant message.
In closing
The emergence of Direct Preference Optimization marks a significant advancement in how we align language models with human preferences. By taking a more direct approach to incorporating human feedback, DPO has streamlined what was previously a complex training process. Research has consistently shown that this simplified approach not only matches but sometimes surpasses traditional methods like RLHF, while using fewer computational resources.
Of course, DPO isn’t without its challenges. The need for extensive high-quality preference data and the risk of overfitting remain important considerations. However, the field isn’t standing still — researchers are actively developing solutions like Identity Preference Optimization (IPO) to address these limitations. Work is also underway to expand DPO’s capabilities, particularly in handling more sophisticated types of feedback.
Looking ahead, DPO’s role in AI development appears increasingly significant. As language models become more deeply woven into our daily lives, the importance of aligning them with human values grows correspondingly. DPO’s approach to creating more human-aligned AI systems suggests a future where artificial intelligence not only serves us more effectively but does so in a way that better reflects human values and ethical considerations.
Connect with me on LinkedIn and GitHub, where I keep sharing such free content to become more productive at building ML systems.
Follow me on X (Twitter) and Medium to get instant notifications for everything new.
Join my YouTube channel for upcoming insightful content.
Subscribe to the UnfoldAI magazine in Substack.
Check my special content on my website.