


ModernBERT — A modernized BERT for NLP tasks
Overview, benchmarks, and fine-tuning notebook


The introduction of BERT (Bidirectional Encoder Representations from Transformers) in 2018 signaled a paradigm shift in Natural Language Processing (NLP).
As the first deep learning model to process text bidirectionally, BERT significantly improved various NLP tasks, including sentiment analysis, named entity recognition, question answering, and text classification. However, despite its revolutionary impact, BERT had limitations, such as a restricted context length (512 tokens), high computational resource demands, and a lack of code awareness.
ModernBERT, a recent advancement in encoder-only models, is a major Pareto improvement over older encoders. It offers enhanced performance and efficiency.

This article goes into the key concepts and improvements of ModernBERT, compares it with previous BERT models, and provides practical examples and details on implementation.
Here, you can find a notebook for fine-tuning ModernBERT.
Before we dive in, I’d like to mention my book “Build RAG Applications with Django”. It covers Django fundamentals, RAG architectures, and AI integration. The book guides you through building selfGPT, a real-world RAG application that transforms your PDFs and text files into interactive AI insights. It includes practical examples of similarity search with pgvector, OpenAI API integration, and optimization techniques. As a bonus, you’ll receive the complete source code for selfGPT. Now, let’s explore ModernBERT!
Key concepts and improvements
ModernBERT distinguishes itself from its predecessors through several architectural enhancements and training methodologies. It is designed explicitly as an encoder-only model, making it leaner and more efficient for tasks that don’t require text generation.
Some of the key improvements include:
Extended context length: ModernBERT boasts a sequence length of 8,192 tokens, a significant leap from the 512 tokens limit in the original BERT. This extended capacity allows it to handle much longer documents or datasets, opening doors to use cases like full-document retrieval and large-scale code analysis.
Improved architecture: ModernBERT incorporates several advancements in transformer architecture:
Rotary Positional Embeddings (RoPE) replace the older positional encoding mechanism, which improves understanding of token positions and enables longer sequence lengths.
GeGLU Layers: ModernBERT substitutes the old MLP layers with GeGLU layers, refining the original BERT’s GeLU activation function for enhanced performance.
Streamlined architecture: ModernBERT streamlines its architecture by removing unnecessary bias terms, allowing for a more efficient allocation of the parameter budget.
Additional Normalization Layer: An extra normalization layer after embeddings contributes to training stabilization.
FlexBERT: ModernBERT introduces FlexBERT, a modular approach to encoder building blocks, further enhancing its architectural flexibility and adaptability.
Integration of Flash Attention 2 and RoPE: ModernBERT integrates Flash Attention and rotary positional embeddings (RoPE) to enhance computational efficiency and positional understanding.
Flash attention and unpadding: ModernBERT employs Flash Attention and unpadding techniques to accelerate training and inference. Flash Attention, a highly efficient attention mechanism, reduces the computational overhead of processing long sequences. Unpadding, on the other hand, eliminates unnecessary padding tokens during the computation process, optimizing memory usage and speeding up operations. ModernBERT leverages Flash Attention 2’s speed improvements, building upon existing research to maximize efficiency.
Alternating attention: ModernBERT utilizes an alternating global and local attention pattern, drawing inspiration from how a human reader processes a novel. Every third layer employs full contextual awareness, while the others concentrate on local context, balancing efficiency and performance 8.
Hardware-aware model design: ModernBERT is designed with hardware in mind, ensuring efficient execution on various GPUs and maximizing performance on commonly used hardware.
Training data and process
ModernBERT was trained on a massive dataset comprising over 2 trillion tokens from a diverse range of sources, including:
This diverse dataset empowers ModernBERT to excel in tasks requiring specialized knowledge, such as code retrieval, programming assistance, and technical document understanding.
Training process: ModernBERT’s training process is divided into three distinct phases:
This phased approach allows the model to progressively enhance its general language understanding while ensuring its proficiency in handling long documents effectively.
ModernBERT significantly improves efficiency and performance compared to its predecessors. This is achieved through architectural innovations, training methodologies, and a focus on hardware optimization.
These combined efforts result in a model that is more accurate, faster, and more memory-efficient, making it suitable for inference on common GPUs.
But why do we need a newer BERT?
ModernBERT offers several advantages over previous BERT models:
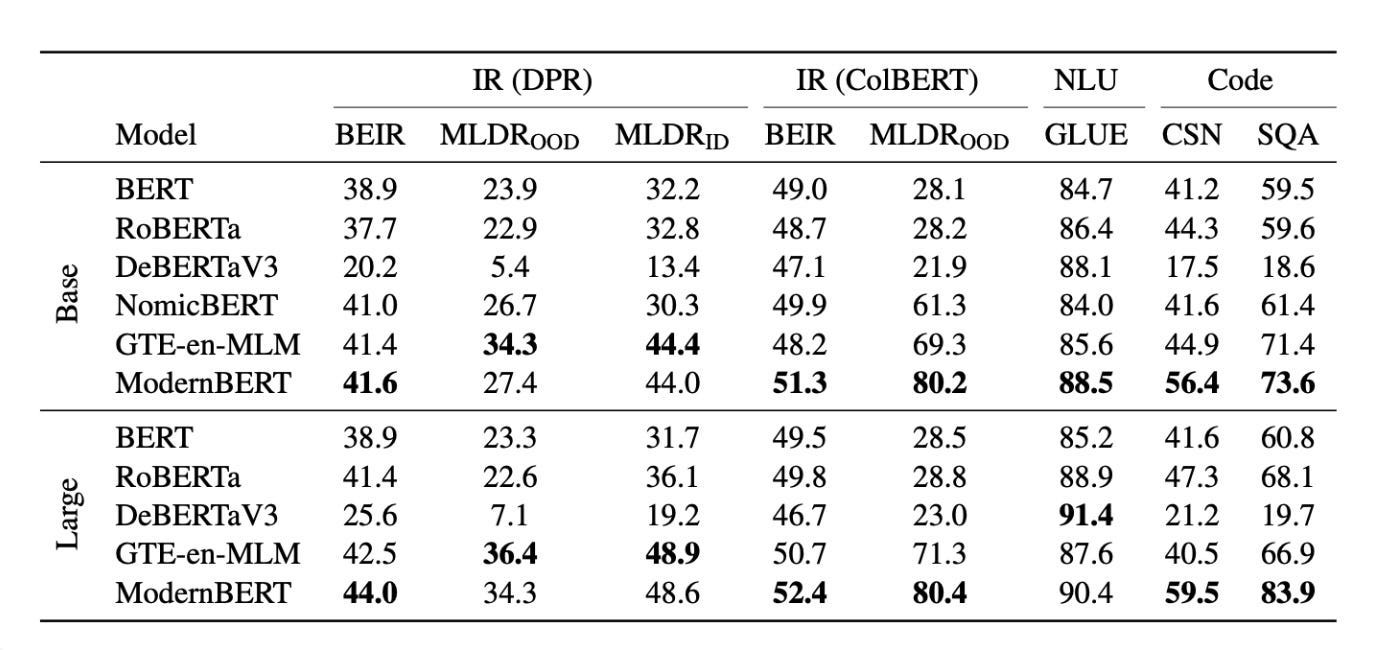
Improved performance: ModernBERT consistently outperforms models like RoBERTa and DeBERTa across various NLP tasks.
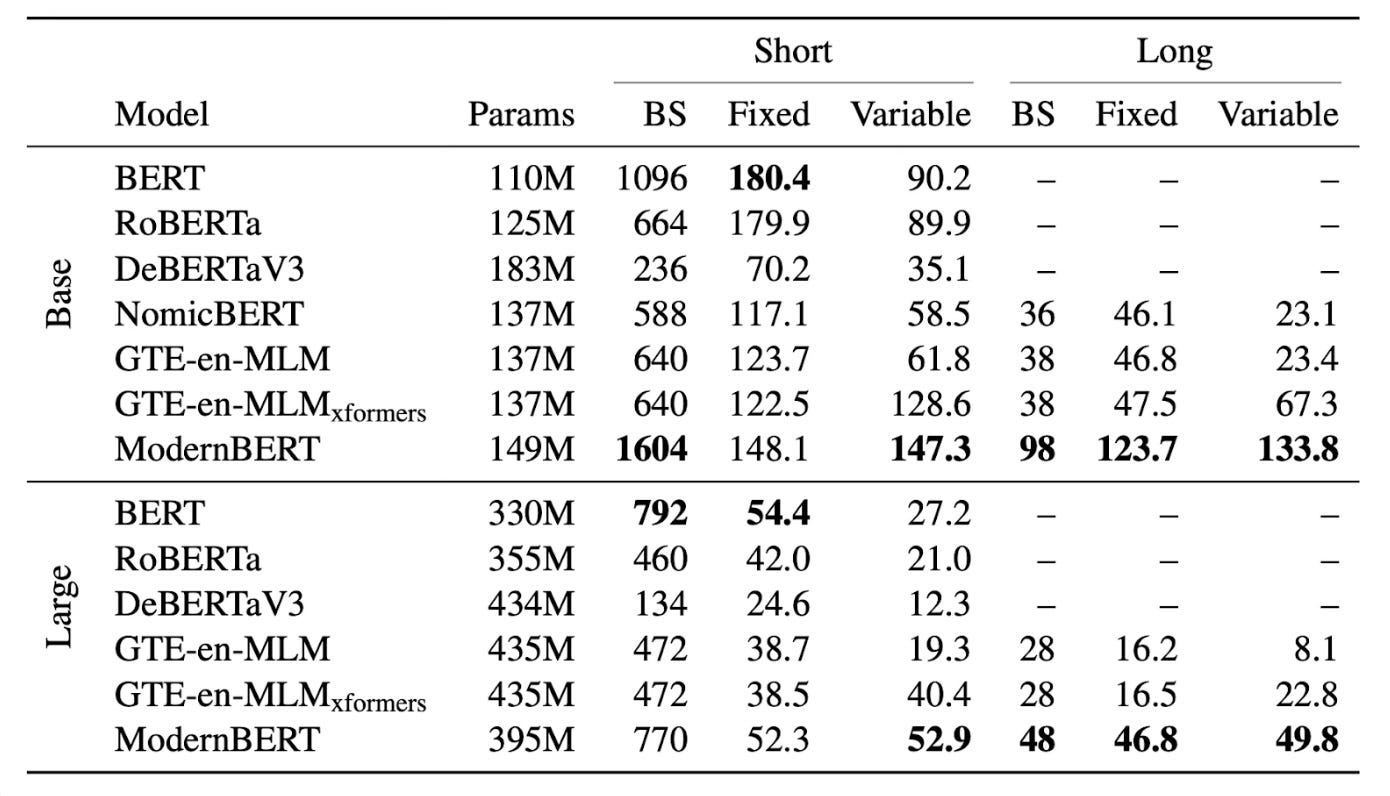
Increased efficiency: ModernBERT’s architectural improvements and training methodologies result in faster processing and reduced memory consumption. 2. It is the most speedy and memory-efficient encoder among its peers.
Longer context length: The extended context length allows ModernBERT to handle longer documents and excel in long-context tasks.
Code awareness: ModernBERT’s training data includes a substantial amount of code, enabling it to perform well on code-related tasks.
Implementing ModernBERT
ModernBERT can be readily implemented using popular NLP libraries like Hugging Face Transformers.
Here’s a basic example of how to use ModernBERT for a fill-mask task:
# Installation from GitHub, as still not included in the current Transformers version
pip install git+https://github.com/huggingface/transformers.gitAnd the Python code:
import torch
from transformers import pipeline
from pprint import pprint
pipe = pipeline(
"fill-mask",
model="answerdotai/ModernBERT-base",
torch_dtype=torch.bfloat16,
)
input_text = "He walked to the [MASK]."
results = pipe(input_text)
pprint(results)This code snippet demonstrates how to use the fill-mask pipeline with the answerdotai/ModernBERT-base model to predict the masked word in a sentence.
You can fine-tune ModernBERT using standard BERT fine-tuning recipes for more complex tasks like classification or retrieval. The Hugging Face Model Hub provides pre-trained ModernBERT models and various resources to help you get started. But in the next part, I will give a simple fine-tuning procedure.
ModernBERT fine-tuning
ModernBERT’s architecture makes it particularly well-suited for fine-tuning specific tasks. Let’s explore how to fine-tune ModernBERT using a practical example of sentiment analysis on Bulgarian text data.
The fine-tuning process adapts the pre-trained model to a specific downstream task while preserving its learned language understanding. This is especially effective because ModernBERT’s pre-training on diverse datasets provides a strong foundation for various NLP tasks.
Let’s walk through a complete example using a Bulgarian sentiment analysis dataset containing 7,923 rows of text with sentiment labels. You can find the implementation in this Colab notebook.
The implementation starts with preparing the data using a custom Dataset class that handles tokenization and creates appropriate tensor formats:
class TextDataset(Dataset):
def __init__(self, data, tokenizer, max_length=128):
self.encodings = tokenizer(data['text'],
truncation=True,
padding=True,
max_length=max_length,
return_tensors='pt')
self.labels = torch.tensor(data['label'])We then set up the model using the base ModernBERT architecture with a classification head and configured the training process with carefully chosen hyperparameters. The training loop includes both training and validation phases, tracking key metrics throughout the process:
model_name = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name,
num_labels=2)
# Training loop
for epoch in range(num_epochs):
model.train()
for batch in train_loader:
optimizer.zero_grad()
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()After training, we evaluate the model on a test set and save both the model and tokenizer for future use:
model.save_pretrained('./modernbert_bulgarian_sa')
tokenizer.save_pretrained('./modernbert_bulgarian_sa')This example demonstrates ModernBERT’s capability to adapt to specific languages and tasks while maintaining efficient training characteristics. You can modify this template for other text classification tasks or different languages with minimal changes to the core architecture.
For hands-on experimentation with this implementation, visit the complete Colab notebook, which provides an interactive environment for running and modifying the fine-tuning process.
This example can be enhanced with several modern optimization approaches that have shown promising results in recent research. Some key improvements could include implementing curriculum learning by gradually decreasing the MLM masking probability during training, which helps the model build understanding progressively. The ADOPT optimizer could replace traditional optimizers for better convergence characteristics, especially in large-scale language model training. Additionally, integrating FlashAttention 2 can significantly accelerate training on compatible GPUs by optimizing attention computation patterns.
The training process could also benefit from dynamic batching with a custom DataCollator to handle varying sequence lengths more efficiently, and gradient accumulation to simulate larger batch sizes without increasing memory requirements.
These techniques, combined with careful hyperparameter tuning and regular evaluation steps, can lead to more robust and efficient fine-tuning of ModernBERT for specific domains and tasks.
Let me know if you’d like to explore a more advanced notebook that implements these optimization techniques — I’d be happy to guide you through a more complicated implementation with curriculum learning, custom data collation, and advanced training monitoring.
Practical examples of ModernBERT
ModernBERT’s enhanced capabilities make it suitable for various NLP applications.
Some practical examples include:
Retrieval Augmented Generation (RAG): ModernBERT’s extended context length and efficient processing make it ideal for RAG pipelines, where it can effectively retrieve and process relevant information from large knowledge bases to augment the generation capabilities of large language models.
Semantic search: ModernBERT can power semantic search engines, enabling more accurate and relevant search results by understanding the meaning and context of search queries and documents.
Code retrieval: ModernBERT excels in code retrieval tasks, achieving high scores on the SQA dataset. This capability can be used to develop AI-powered IDEs and enterprise-wide code indexing solutions.
Classification: Modern BERT can be fine-tuned for various classification tasks, such as sentiment analysis, topic classification, and spam detection, and it performs better than previous BERT models.
Question answering: ModernBERT can be used in question-answering systems. By effectively understanding the context and meaning of queries and relevant documents, it can provide accurate and comprehensive answers.
ModernBERT represents a step forward in the evolution of encoder-only models. By incorporating modern architectural improvements, efficient training methodologies, and a diverse training dataset, ModernBERT addresses the limitations of previous models and offers enhanced performance and capabilities. Its extended context length, improved efficiency, and code awareness make it a versatile tool for various NLP applications, including semantic search, classification, code retrieval, and RAG pipelines.
The impact of ModernBERT extends beyond improved benchmarks. Its design for real-world performance with variable-length inputs makes it a practical and valuable tool for various industries and applications. Whether it enhances search engine accuracy, powers code retrieval systems, or improves the efficiency of NLP pipelines, ModernBERT has the potential to impact how we interact with and utilize language data significantly.
Connect with me on LinkedIn and GitHub, where I keep sharing such free content to become more productive at building ML systems.
Follow me on X (Twitter) and Medium to get instant notifications for everything new.
Join my YouTube channel for upcoming insightful content.
Subscribe to the UnfoldAI magazine in Substack.
Check my special content on my website.